Algorithm¶
Calculation order¶
In a cash flow model, variables often depend on other variables, creating a complex web of dependencies. To prevent recursion errors and ensure accurate calculations, the model follows a specific order when processing these variables.
Directed Graph: The model identifies dependencies by creating a directed graph, revealing which variables call other variables.
Initialization: Variables without any predecessors are calculated first. They are removed from the graph, and the process continues until all such variables are processed.
Handling Cycles: If there are variables with cyclic dependencies, they are assigned the same calculation order index and computed simultaneously.
This approach guarantees that variables are calculated in an order that respects their dependencies and mitigates the risk of recursion errors.
Ordering example¶
Step 1: The model consists of 8 variables. Two of these variables, A and B, do not have any predecessors.
To determine the calculation order, we start with the first variable in alphabetical order, which is A.
We assign it a calculation order of 1 and remove it from the calculation graph.
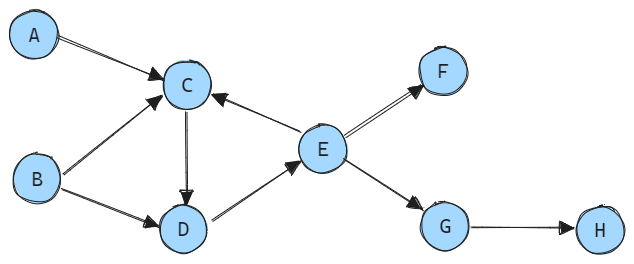
Step 2: Now, the only remaining variable without predecessors is B.
We assign it a calculation order of 2 and remove it from the graph.
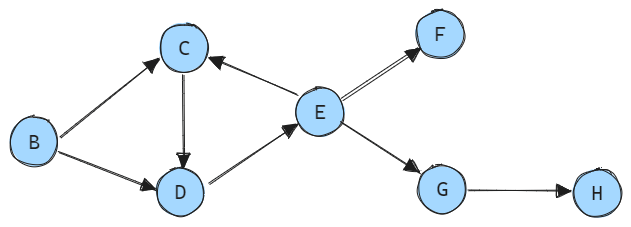
Step 3: At this point, there are no more variables without predecessors because there is a cyclic dependency between variables C, D, and E.
To handle cyclic dependencies, we assign the entire cycle the same calculation order, which is 3, indicating that these variables will be evaluated simultaneously.
Afterward, all three variables are removed from the graph.
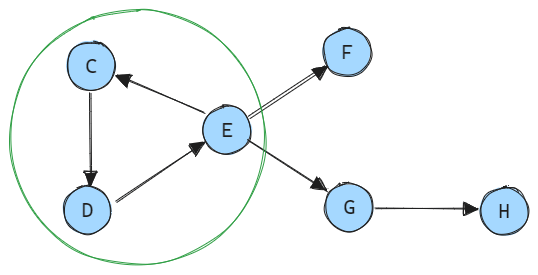
Step 4: The process continues until all variables have been assigned a calculation order.
The next variables to be processed are F with an order of 4, G with an order of 5, and H with an order of 6.
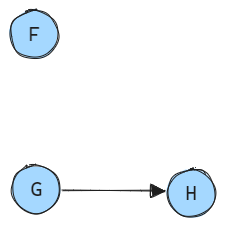
Output subset¶
Users have the flexibility to choose a specific subset of output variables through the OUTPUT_VARIABLES setting.
For instance, let’s consider a scenario where the user has configured their settings to output only the variable F:
settings = {
"OUTPUT_VARIABLES": ["F"],
}
In this case, variables G and H are not required for the desired output and can be safely omitted from the calculation graph and the model itself.
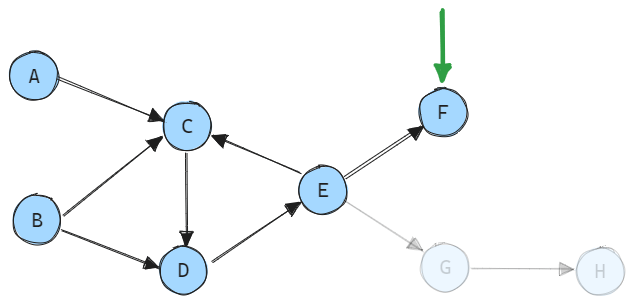
The model only needs to evaluate variable F and its predecessors.